「圧倒的図解で学ぶ Transfomer 徹底解説」動画の AI 整理
(全体俯瞰 : AI 生成) click で拡大
 情報源
情報源
前置き
ChatGPT は Chat Generativve Pre-trained "Transformer" の略だが、その最後の Transformer という仕組みが現在の AI ブームを引き起こした。
Transfomer の解説は書籍や Web 記事でも多数見かけるが、AI の素人がそれらの解説で「何がどうなっているのか」を理解できるとは全く思えない。そんな AI 素人向けの解説がこの 100分を超える解説動画。
この動画を NotebookLM で整理したが、以下には動画に登場する肝心の図解がないので、最初に動画を視るべき。動画を視た後に以下の解説を読むと理解が進むはず。たぶん、1回の視聴では頭が over-flow するので 2, 3回繰り返して視ると解った気になれる筈。
なお、行列演算の基礎知識があるほうが理解しやすいので、高校/大学で習わなかった人は線形代数の初歩を予めざっと頭に入れておいた方がよい。行列は数字を縦横に並べただけの易しいものなので簡単に理解できる筈。(因みにテンソルはその行列に共変・反変という座標変換の制約を付加したもので、これが�一般相対論で使われる)
以下、情報源を NotebookLM で整理した内容。
要旨
提供されたテキストは、現代の生成AIにおける最重要基盤技術であるTransformerの仕組みを、京都大学博士の視点から詳細に解説した講義資料です。
エンコーダーとデコーダーという二つの主要な役割に加え、文章の文脈を理解するための自己注意機構(セルフアテンション)の計算プロセスが、専門的な図解とともに体系化されています。特に、単語間の関係性を数値化するクエリ(Q)・キー(K)・バリュー(V)の働きや、計算効率を高める並列処理の優位性が論理的に説明されているのが特徴です。
また、従来のRNNやCNNと比較した際の長距離依存性の理解能力についても触れ、技術的な進化の系譜を解き明かしています。さらに、学習時のリークを防ぐマスキングや、最終的な単語出力を決定する逆埋め込みまで、実装レベルの構成要素が網羅されています。
全体を通して、ChatGPTなどの大規模言語モデルを深く理解するための「新しい教科書」として、基礎から応用までを丁寧に紐解く内容となっています。
目次
- 前置き
- 要旨
- Transformer技術解説ブリーフィング:現代生成AIの基盤構造とその革新性
- Transformerアーキテクチャの主要構成要素と役割
- Transformer技術解説:現代生成AIの基盤アーキテクチャ
- メカニズム比較読本:なぜ「Transformer」が世界を変えたのか? 従来技術の限界と革新の全貌
- 「春はあけぼの」で読み解くTransformer:言葉が「文脈」を纏う魔法の仕組み
- Transformer移行と次世代AI基盤構築のための戦略的選定ガイド
- 全体像(Encoder-Decoder)
- 主要コンポーネント
- 前処理・後処理
- 情報源
Transformer技術解説ブリーフィング:現代生成AIの基盤構造とその革新性
エグゼクティブ・サマリー
本資料は、現代の生成AI(LLM)の基盤技術である「Transformer」の構造と動作原理について、その革新性と主要コンポーネントを詳説するものである。Transformerは、従来のRNN(再帰型ニューラルネットワーク)やCNN(畳み込みニューラルネットワーク)が抱えていた「長距離依存性の理解」と「並列計算の効率性」のトレードオフを、独自の「自己注意機構(Self-Attention)」によって解消した。BERTやGPTといった主要モデルの基礎となり、テキストのみならず画像生成(CLIP等)にも応用されるなど、AI技術のパラダイムシフトを引き起こした。本ドキュメントでは、エンコーダー・デコーダー構成から各部品の数学的役割まで、その全貌を網羅的に解説する。
1. Transformerの基本概念と革新性
Transformerは、ある系列を別の系列に変換する「Seq-to-Seq(系列対系列変換)」タスク(翻訳、要約など)を解くためのモデルとして提案された。
1.1 従来モデルとの比較と優位性
従来の深層学習モデルには、以下の限界が存在した。
- RNNの限界: 系列を順番に処理するため、前の計算��が終わるまで次へ進めず、並列計算(効率化)が困難であった。
- CNNの限界: 離れた位置にある要素間の関係(長距離依存性)を理解するためには、層を深く重ねる必要があった。
Transformerの解決策: 「Attention is All You Need(注意こそがすべて)」という主張の通り、RNNやCNNを一切排除し、自己注意機構(Self-Attention)のみを採用。これにより、系列内の全要素を同時に参照しながら、離れた要素間の文法的・意味的関係を効率的に学習することを可能にした。
2. アーキテクチャの全体像
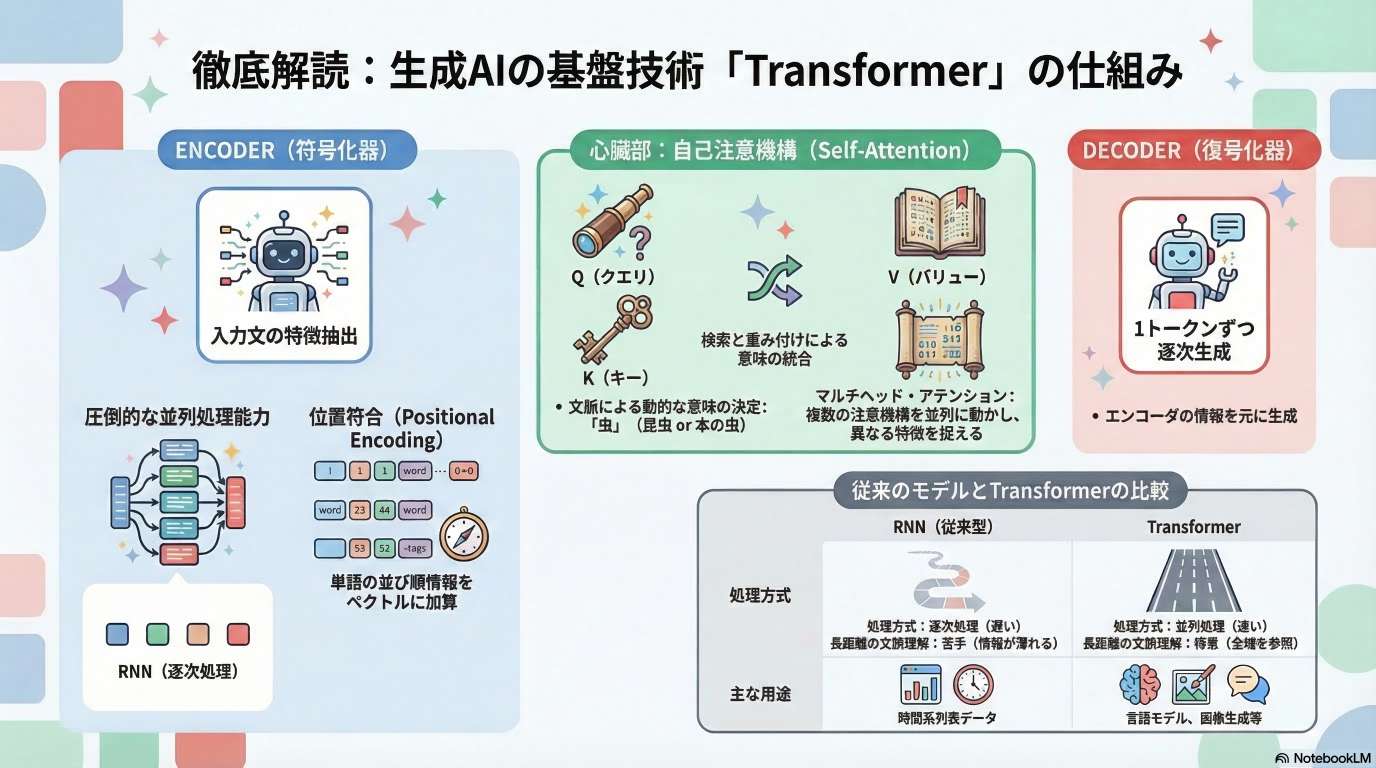
Transformerは大きく「エンコーダー」と「デコーダー」の2つのネットワークで構成される。
2.1 エンコーダー(Encoder)
入力データの「特徴量」を抽出する役割を担う。
- 入力されたテキスト(トークン)を意味的なベクトル表現に変換する。
- 文脈を考慮した特徴抽出を行い、デコーダーへ情報を渡す。
2.2 デコーダー(Decoder)
エンコーダーの特徴量と、それまでに自身が生成したトークンを基に、次に続くべきトークンを予測(生成)する。
- 自己回帰的(Autoregressive)な構造: 1つの予測結果が次のステップの入力となり、ループを回すことで一連の文章を生成する。
3. 入力処理:埋め込みと位置符号化
テキストを数値計算可能な形式に変換するための前処理工程。
プロセス 内容 役割 埋め込み (Embedding) 単語(トークン)を「Dモデル」次元のベクトルに変換する。 トークンの文法的・意味的特徴を数値化する。 位置符号化 (Positional Encoding) 各トークンの位置情報を示すベクトルを多し算する。 Transformer自体が持たない「語順の情報」を認識させる。 4. 自己注意機構(Self-Attention)のメカニズム
Transformerの核心部であり、文脈を考慮して「ベクトルをどれくらいの強さで混ぜ合わせるか」を決定する装置。
4.1 クエリ(Q)、キー(K)、バリュー(V)の概念
各トークンのベクトルから、3つの異なるベクトルを計算する。
- Query (Q): 注意を向けたい起点(探しに行く側)。
- Key (K): 注意を向けられる対象のインデックス(探される側)。
- Value (V): 実際に混ぜ合わせる情報の本体。
4.2 計算プロセス
- 類似度の算出: QとKの内積を計算し、スケーリングとSoftmax関数を適用して「注意重み(Attention Weights)」を算出する。
- 情報の混合: 算出された重みに基づいてVの加重和を計算する。
- 例:「本の虫」というフレーズで「虫」を処理する場合、周囲の「本」というトークンに高い注意を向けることで、「虫」が生物ではなく比喩表現であることを理解したベクトルへと更新される。
4.3 マルチヘッド化(Multi-Head Attention)
単一の注意機構ではなく、次元を小さくした複数の「ヘッド」を並列で走らせる。
- 各ヘッドが「文法的特徴」「常識的知識」など、異なる側面から特徴を抽出することで、多角的な理解を可能にする。
5. デコーダー固有の機能
デコーダーには、生成を正しく行うための特殊な機構が備わっている。
5.1 マスク付き自己注意(Masked Self-Attention)
学習時、未来のトークン情報が見えないように注意を制限する。
- 本来、水論時には未来のトークンは存在しないため、学習時も「自分より後のトークン」への注意重みを強制的にゼロにする。
5.2 交差注意(Cross-Attention)
デコーダーが生成中の情報と、エンコーダーが抽出した入力側の特徴を混ぜ合わせる。
- これにより、「入力文のどの部分に注目して翻訳・要約すべきか」を判断する。
6. フィードフォワード層と最終出力
6.1 フィードフォワードネットワーク (FFN)
各トークンのベクトルに対して独立に適用される全結合ニューラルネットワーク。
- アフィン変換、ReLU活性化関数、再度の維持変換のプロセスを経て、ベクトルの表現力を高める。
6.2 逆埋め込み(Un-embedding)とトークン予測
デコーダーの最終層から出力されたベクトルを、元の語彙数(V次元)の確率分布に戻す処理。
- 最も確率の高いトークン、あるいは「ビームサーチ」等の手法で選ばれた最適なトークンが最終的な出力となる。
- 「文末トークン(End of Sentence)」が予測されるまで生成ループが繰り返される。
7. 発展と展望
Transformerの基本構造は、現在も急速に進化を続けている。
- RoPE (Rotary Positional Embedding): 回転行列を用いたより高度な位置情報の表現。
- MoE (Mixture of Experts): FFN部分を専門家集団のようなネットワークに置き換え、効率を向上させる手法。
- マルチヘッド・ラテン・アテンション: メモリ圧迫を抑えるための注意機構の発展型。
Transformerは「共通の次元(Dモデル)で全層を処理する」という美しい構造を持つ。この特性を活かし、途中の層がどのような予測を行っているかを分析する「ロジットレンズ(Logit Lens)」といった研究手法も確立されている。
Transformerアーキテクチャの主要構成要素と役割
コンポーネント名 主な役割・機能 特徴的な計算・メカニズム 位置付け(エンコーダ/デコーダ) エンコーダ 入力されたテキスト(トークン列)から意味的・文法的な特徴量を抽出する。 自己注意機構(セルフアテンション)により、全域的なトークンの参照を行い特徴抽出を並列に実行する。 エンコーダ デコーダ エンコーダの出力と自身の生成済みトークンに基づき、次に続くトークンを予測生成する。 マスク付き自己注意、交差注意、自己回帰的なループ構造(ループごとに1トークンを予測)。 デコーダ 自己注意機構(Self-Attention) 系列内の離れた位置にある要素間の関係(長距離依存)を理解し、文脈を考慮したベクトル表現に更新する。 クエリ(Q)、キー(K)、バリュー(V)を用いた内積計算とソフトマックス関数による重み付け和。 エンコーダ/デコーダ(両方) マルチヘッドアテンション 複数の注意機構を並列で走らせることで、多様な観点からの特徴抽出と学習効率・性能の向上を図る。 Q, K, Vを低次元に分割(ヘッド化)して並列計算し、最後にそれらを結合して線形変換する。 エンコー��ダ/デコーダ(両方) マスク付き自己注意機構 デコーダにおいて、未来のトークンを参照しないように情報を制限する。 先行するトークンのみを考慮するよう、未来位置の注意重みを強制的に0(またはマイナス無限大)にする。 デコーダ 交差注意機構(Cross-Attention) エンコーダが抽出した入力側の特徴と、デコーダ側の情報を混ぜ合わせる。 クエリ(Q)をデコーダ側から、キー(K)とバリュー(V)をエンコーダ側から受け取ってアテンションを計算する。 デコーダ 位置符号(Positional Encoding) 自己注意機構が認識できないトークンの並び順(位置情報)をベクトルに付与する。 位置ごとに固有のベクトルを計算(または学習)し、トークンの埋め込みベクトルに加算する。 エンコーダ/デコーダ(両方) フィードフォワードネットワーク(FFN) 自己注意機構で抽出された各ベクトルの特徴を個別に非線形変換し、表現力を高める。 線形変換、活性化関数(ReLUなど)、再度線形変換の2層構造。各トークン位置で個別に適用される。 エンコーダ/デコーダ(両方) 残差接続と層正規化 学習の安定化と、多層化による情報の消失を防ぐ役割を持つ。 各サブレイヤーの入力を出力に足し合わせる(残差接続)とともに、値を正規化する。 エンコーダ/デコーダ(各ブロック内) 埋め込み(Embedding) / 逆埋め込み テキストを数値計算可能なベクトルに変換、または最終ベクトルをトークンの確率分布に変換し戻す。 埋め込み行列によるベクトル抽出。最後は線形変換とソフトマックスで次に続く語の確率を算出する。 入力/出力(両方) [1] 圧倒的図解で学ぶ「Transformer」徹底解読【Attention is All You Need】
Transformer技術解説:現代生成AIの基盤アーキテクチャ
エグゼクティブ・サマリー
本資料は、現代の生成AI(Generative AI)の根幹をなす技術アーキテクチャ「Transformer」についての包括的なブリーフィング・ドキュメントである。Transformerは、BERTやGPT、CLIP、Vision Transformer(ViT)など、言語・画像の両分野における主要なAIモデルの基盤となっている。
最大の革新点は、従来のRNN(再帰型ニューラルネットワーク)やCNN(畳み込みニューラルネットワーク)が抱えていた「並列計算の困難さ」と「長距離依存性の理解」というトレードオフを、自己注意機構(Self-Attention)のみを用いることで解消した点にある。本ドキュメントでは、エンコーダー・デコーダー構造から、QKV(Query, Key, Value)モデルに基づく注意機構の数学的プロセス、そして最新のLLMへと繋がる発展��的要素までを詳説する。
1. アーキテクチャの全体像
Transformerは、入力系列を別の系列に変換する「Sequence-to-Sequence (Seq2Seq)」タスクを解くためのネットワークとして提案された。
エンコーダーとデコーダーの役割
- エンコーダー(Encoder): 入力されたテキスト(トークン列)から意味的・文法的な特徴量を抽出する。
- デコーダー(Decoder): エンコーダーが抽出した特徴量と、それまでに自身が生成したトークン列に基づき、次に来るべきトークンを一つずつ予測(自己回帰的な生成)する。
従来モデルとの比較
モデル型 特徴 課題 RNN 系列理解に強い。順番に処理を行う。 前の計算が終わるまで次へ進めず、並列処理・効率化が困難。 CNN 並列化が可能。局所的な特徴抽出に長ける。 遠く離れた要素間の関係(長距離依存性)を捉えるには多層化が必要。 Transformer 自己注意機構(Self-Attention)を採用。 依存関係を排除し、並列計算と長距離依存性の理解を両立。 2. 前処理と入力表現:埋め込みと位置符号
Transformerが数値を処理する前段階として、テキストをベクトル空間へ投影する処理が行われる。
埋め込み(Embedding)
辞書内の全トークン数(V)に対し、モデル内で一貫して使用される次元数(D-model)のベクトルを割り当てる。ワンホットベクトルに行列(E)を掛けることで、特定のトークンに対応する埋め込みベクトル(X)を抽出する。
位置符号(Positional Encoding)
Transformerの自己注意機構は、単体ではトークンの並び順(語順)を認識できない。そのため、各位置に対応する固有のベクトル(P)を埋め込みベクトルに加算することで、位置情報を付与する。近年では「RoPE(Rotary Positional Embedding)」のような回転行列を用いた手法も発展している。
3. 自己注意機構(Self-Attention)の本質
Transformerの「心臓部」であり、各トークンが周辺のトークンをどの程度参照すべきかを動的に決定する仕組みである。
QKVモデルによる演算プロセス
- クエリ(Query): 注意の起点となるベクトル。「どの情報に注目したいか」を示す。
- キー(Key): 注意の対象となるベクトル。「どのような情報を保持しているか」というラベルの役割を果たす。
- バリュー(Value): 実際に混ぜ合わせる情報の本体。
計算手順
- 類似度の算出: クエリ(Q)と各キー(K)の内積を計算する。内積が大きいほど、そのトークン同士の関係性が強い(類似度が高い)と見なされる。
- 正規化とスケーリング: 次元の大きさによる影響を抑えるため、次元数(dk)の平方根で割り、ソフトマックス関数を適用して「注意重み(Attention Weight)」を得る。
- 情報の集約: 算出された重みに基づいてバリュー(V)を重み付け加算する。これにより、文脈を考慮した「動的な埋め込み(Dynamic Embedding)」が実現される。
4. 発展的な注意機構とコンポーネント
Transformerの性能と効率を支える高度な構造について解説する。
マルチヘッド・アテンション(Multi-Head Attention)
単一の注意機構ではなく、次元を縮小した複数の「ヘッド」で並列に注意計算を行う。各ヘッドが文法的特徴や常識的知識など、異なる側面の特徴を抽出することで、より多角的な理解を可能にする。
マスク付き自己注意(Masked Self-Attention)
デコーダー側で使用される。学習時、未来のトークン情報(カンニング)を見せないように、未来方向への注意重みを強制的にゼロ(実務上はマイナス無限大)にする処理である。
交差注意(Cross Attention)
デコーダーがエンコーダーの出力を参照する仕組み。デコーダー由来のクエリ(Q)と、エンコーダー由来のキー(K)・バリュー(V)を用いることで、�入力情報の文脈を生成プロセスに取り込む。
5. 内部ブロックの補助機構
フィードフォワード・ネットワーク(FFN)
自己注意機構の後に配置される、2層の線形変換と活性化関数(ReLUなど)からなる層。各トークンのベクトルに対して個別に適用され、さらなる特徴変換を行う。
残差接続(Residual Connection)と層正規化(Layer Normalization)
- 残差接続: 入力ベクトルを処理後の結果に直接加算する。これにより勾配消失を防ぎ、情報の伝達を安定させる。この加算の連鎖は「レジジュアル・ストリーム(Residual Stream)」と呼ばれ、情報の更新過程を分析する対象となる。
- 層正規化: 学習の効率化と安定化のために行われる。
逆埋め込み(Un-embedding)
デコーダーの最終層から出力されたベクトルを、再び語彙次元の確率分布へと変換する処理。埋め込み行列(E)の転置を用いることで、ベクトルと最も類似したトークンを特定する。生成の最終段階では、確率が最大のトークンを選ぶ手法のほか、複数の候補を保持する「ビームサーチ(Beam Search)」などが用いられる。
結論
Transformerは、RNNのような逐次処理の制約を打破し、注意機構によって全域的なコンテキストを並列に処理する道を切り拓いた。この��アーキテクチャは、単なる言語翻訳の枠を超え、現代のLLMにおける混合専門家(Mixture of Experts)やロジットレンズ(Logit Lens)分析など、多方面の技術的発展の礎石となっている。
メカニズム比較読本:なぜ「Transformer」が世界を変えたのか? 従来技術の限界と革新の全貌
1. はじめに:学習のロードマップと「なぜ」の提示
現代のAI(GPTやBERTなど)の圧倒的な能力を支えている基盤技術、それが「Transformer(トランスフォーマー)」です。しかし、この技術の本質を理解するためには、まず「なぜ従来の技術では到達できなかったのか?」という壁を知る必要があります。
本書では、かつてのAIが抱えていたジレンマをどう突破し、どのようにして「言葉」をデジタルな宇宙として再構築したのか、その革命の全貌を解き明かします。学習のポイントは以下の3点です。
- 従来技術(RNN/CNN)の限界:並列処理と長距離の理解という「二律背反」の正体を知る。
- Attention(注意)の魔力:Q・K・Vという「検索エンジン」の仕組みで、情報の混ぜ合わせを理解する。
- 理解から生成へのプロセス:エンコーダーとデコーダーが、情報をどう紡ぎ、どう言葉に戻すのかを俯瞰する。
2. 従来技術の限界:RNNとCNNの「二律背反」
Transformer以前、自然言語処理の主役はRNN(再帰型ニューラルネットワーク)であり、並列処理が得意なCNN(畳み込みニューラルネットワーク)も活用されていました。しかし、これらは「速度」か「距離」のどちらかを犠牲にする必要がありました。
従来技術の比較表
項目 RNN(再帰型) CNN(畳み込み型) 処理の進め方 1文字ずつ順番に処理(逐次処理) 一定の範囲をまとめて処理(並列処理) 計算コストの特性 文の長さに比例して時間が増大(O(N)) 層を重ねることで広範囲をカバー 決定的な弱点 並列計算が不可能。GPUのパワーを活かせない。 長距離依存性の欠如。離れた言葉の関係が捉えにくい。 「一歩ずつのRNN」と「近視眼的なCNN」
�例えば、「私は、昨日の放課後、図書室で……(中略)……本の虫になった」という長い一文を考えてみましょう。
- RNNの限界: 文の最後にある「虫」に到達するまでに、文頭の「私」や「図書室」という情報を忘れてしまう「勾配消失」が起きます。また、前の計算が終わるまで次へ進めないため、最新のGPUを使っても「順番待ち」が発生し、学習に膨大な時間がかかっていました。
- CNNの限界: 近くの単語の組み合わせは得意ですが、文頭と文末のように離れた関係を理解するには、フィルタを何重にも積み重ねる必要があり、構造が複雑で非効率でした。
3. 魔法の杖「Attention(注意)」:情報の混ぜ合わせの極意
Transformerの核となるSelf-Attention(自己注意機構)は、各単語が文中の他のすべての単語に対して「自分にとってどれくらい重要か」を自ら計算する仕組みです。
「辞書検索」のメタファーで理解するQ・K・V
Self-Attentionの計算は、インターネットの検索エンジンのような「情報のマッチング」に例えられます。
- Q (Query): 「私は今、何に注目したいか?」という検索クエリ。
- K (Key): 各単語が持つ「私はこういう情報を持っています」というインデックス(ラベル)。
- V (Value): その単語に蓄えられてい�る情報の正体(中身)。
「春はあけぼの」の例で見る情報の合成
「春はあけぼの」や「本の虫」というフレーズを処理する際、「虫」という単語単体(V)だけでは、カブトムシか読書家か判断できません。しかし、Self-Attentionは「虫」というQに対し、周囲の「本」というKが高い類似度を持つことを見抜きます。
- 類似度の計算: QとKを掛け合わせ(内積)、類似度を出します。
- 重み付け: ソフトマックス関数で正規化し、合計1(100%)の「注意の重み」に変換します。
- 情報の合成: この重みに基づき、各単語のV(中身)をギュッと混ぜ合わせます。
この結果、「虫」のベクトルに「本」の情報が混ざり合い、「読書家」という正しい文脈を纏った高次元の表現へとアップデートされるのです。
4. エンコーダーの役割:文脈の徹底的な「理解」
エンコーダーの目的は、入力されたテキストから、その意味や文法的なつながりを凝縮した「高次元の特徴量」を抽出することです。このプロセスでは、モデル全体で一貫した次元数であるD_{model}が維持され、情報の劣化を防ぎます。
エンコーダーの処理ステップ
- エンベディングと位置符号(Positional Encoding): テキストをベクトル化します。Transformerは全単語を同時に処理するため、そのままでは「単語の袋(Bag of Words)」状態になり順序が失われます。そこで、位置情報を足し合わせることで、順序の概念を付与します。
- マルチヘッド自己注意: 複数の「視点(ヘッド)」で同時に注意を計算します。あるヘッドは「文法」に、別のヘッドは「常識的なつながり」に注目するなど、多角的な理解を実現します。
- フィードフォワード層: Attentionで混ぜ合わされた情報を、各単語ごとに個別に整理・整頓します。
5. デコーダーの役割:未来を予測する「生成」のメカニズム
デコーダーは、エンコーダーが作った「意味の塊」を読み解き、一文字ずつ順番に答えを紡ぎ出す「自己回帰的」なネットワークです。
デコーダー特有の重要機能
- マスク付きSelf-Attention: 学習時、AIが「未来の単語」を見てカンニングするのを防ぐ仕組みです。まだ出力していない単語への注意を強制的にゼロにし、過去の情報だけで未来を予測する力を養います。
- クロス・アテンション(交差注意): 自分が今書いている文と、エンコーダーが解析した原文を照らし合わせます。「原文のどこに注目して次の単語を訳すべきか」を判断する、翻訳の要となる工程です。
レジジュアル・ストリームと情報の流れ
Transformerの各層には、処理前の情報をそのまま後ろに流す「残差接続」があります。情報は「レジジュアル・ストリーム(情報の奔流)」として層を駆け抜け、各層はそこに必要な情報を「書き込む」ように動作します。これにより、情報の消失を防ぎつつ、途中の層が何を考えているかを分析する「サーキット分析」や「ロジットレンズ」といった高度な解析が可能になります。
生成の完了:EOSトークンと逆埋め込み(Reverse Embedding)
生成は、辞書に含まれるEOS(End of Sentence)という特殊な終端トークンが選ばれるまでループします。 最後に、デコーダーが導き出した最強のベクトルを、最初に使ったエンベディング行列の転置(E^T)を用いて、全単語リストと照合します(内積計算)。これにより、ベクトルが再び「言葉」へと戻り、私たちが目にするテキストが完成します。
6. まとめ:Transformerがもたらしたパラダイムシフト
Transformerの登場は、単なる技術改善ではなく、AIが「世界を理解する作法」そのものの転換でした。
RNNの「一歩ずつ進む逐次処理」から、Transformerの「全域的・並列的処理」への移行は、AIの学習スピードと表現力を別次元へと引き上げました。この技術が、現在のGPTやBERT、さらには画像や音声のAIへと繋がる巨大な扉を開いたのです。
Transformerの核心を一言で表せば、それは「文中のあらゆる単語間の距離をゼロにし、全域的な関係性を一瞬で見抜く、究極の並列理解装置」である。
この「距離がゼロになる」という革命によって、AIはかつてないほど深く、そして広大な知性を手に入れました。次にあなたが触れるBERTやGPTの裏側でも、このQ・K・Vの華麗なダンスが、静かに、しかし力強く踊り続けているのです。
「春はあけぼの」で読み解くTransformer:言葉が「文脈」を纏う魔法の仕組み
1. はじめに:Transformerが変えたAIの世界
みなさん、こんにちは。今日は現代の生成AIの心臓部であり、知能の革命を引き起こした「Transformer(トランスフォーマー)」という魔法の正体を解き明かしていきましょう。
かつてAIが言葉を理解しようとしたとき、それは暗い夜道を一歩ずつ足元だけを見て歩くようなものでした。�以前の主流だった技術(RNNなど)は、言葉を一つずつ順番に処理していたため、長い文章の最初の方を忘れてしまったり、計算に膨大な時間がかかったりするという宿命的な弱点を持っていたのです。
しかし、Transformerの登場によって世界は一変しました。それは、一歩ずつ歩くのをやめ、空から風景全体を一瞬で俯瞰するような革命です。
- 長距離依存性の理解(正確性)
- 文章の最初と最後にある言葉が、どれほど離れていてもその関係性を一瞬で、正確に捉えることができます。
- 並列処理の実現(スピード)
- 言葉を順番に読み上げるのではなく、文章全体を「一撃」で同時に処理できるため、驚異的な学習速度を実現しました。
Transformerとは、入力された系列(例えば日本語の「春はあけぼの」)を、別の系列(英語の "Spring is the dawn")へと変換する魔法の翻訳機です。では、言葉が数値の輝きを纏い、命を吹き込まれる準備段階から覗いてみましょう。
2. 言葉を数値の輝きへ:埋め込み(Embedding)と位置符号(Positional Encoding)
AIは文字をそのままでは理解できません。私たちが「春」という言葉に暖かさや芽吹きを感じるように��、AIにとっても「春」を意味のある数値の塊、すなわちベクトルに変える必要があります。
埋め込み(Embedding)
ここでは「埋め込み行列 E」という、人類の全語彙を網羅した壮大な「意味の地図」が登場します。この地図の中で、「春」や「犬」は特定の座標(ベクトル)として存在しています。
【言葉を数値に変えるステップ】
- ワンホットベクトル: 辞書(V 次元)の中で「春」という言葉の場所だけを「1」にし、残りを「0」にした橋渡し役のベクトルを作ります。
- 埋め込み行列 E との出会: この橋渡し役を、AIが学習で獲得した巨大な地図(V \times D_{model} 行列)に掛け合わせます。
- 輝きの抽出: すると、地図から「春」という言葉が持つ文法的・情緒的な特徴が凝縮された D_{model} 次元のベクトル X が取り出されます。
位置符号(Positional Encoding)
ここで一つ問題があります。Transformerは全てを同時に見るがゆえに、そのままでは「春はあけぼの」も「あけぼのは春」も同じ単語セットとしてしか認識できません。そこで、語順という「時間」の情報を刻印するために、位置情報というスパイスをベクトルに足し算します。
これにより、AIは「この『春』は文章の先頭に咲いている」という場所を認識できるのです。今、言葉たちは自分の居場所を見つけ、お互いに語り合う準備が整いました。
3. 文脈を編み上げる魔法:自己注意機構(Self-Attention)の正体
いよいよTransformerの心臓部、自己注意(Self-Attention)の出番です。「春はあけぼの」という言葉の並びを想像してください。「春」という言葉は、後ろに「あけぼの」があることで、ただの季節から「紫に色づく夜明け前」という鮮烈な情景へと意味を深化させます。
この「周辺の言葉を見て、自分の意味をダイナミックに進化させる」仕組みこそが、自己注意の正体です。
Q, K, V の役割比較
AIは各単語から3つの役割を持つベクトルを作り出し、言葉同士の「お見合い」をさせます。
項目 メタファー 役割(言葉の心の動き) クエリ (Q) 切実な問いかけ 「私は今、誰に注目すべき?(私は誰?)」 キー (K) アイデンティティの札 「私はこういう特徴を持っていますよ」 バリュー (V) 意味の提供者 「私が差し出せる、文脈の深みそのもの」 例えば「虫」という単語。これだけではカブトムシか何かでしょう。しかし、クエリ(Q)が近くの「本」というキー(K)と強く反応したとき、その「本」の持つ意味(V)が「虫」のベクトルにギュッと混ぜ合わされます。すると、冷たい数値だった「虫」は、知性溢れる「本の虫(読書家)」という熱を帯びた文脈を纏うのです。
4. チー��ムで理解を深める:マルチヘッド・アテンションとFFN
Transformerは、この自己注意をより贅沢に使いこなします。
マルチヘッド・アテンション:専門家チームの合議制
一つの視点(ヘッド)だけで文章を見るのではなく、複数の視点を持つ専門家チームを構成します。「文法担当」「季節の情景担当」「歴史の重み担当」……。彼らが並列して分析を行うことで、多次元的な理解が可能になります。
- 分割: 言葉のベクトルを細かく分け、各ヘッドに配分します。
- 並列計算: 専門家たちがそれぞれの視点で、同時に自己注意を計算します。
- 結合: 全員の分析結果を一つに統合し、再び一つの力強いベクトルへと再構成します。
フィードフォワードネットワーク(FFN):個の磨き上げ
チームでの会議が終わった後は、各単語(ベクトル)を個別にブラッシュアップする個別の磨き上げ作業に入ります。ここでは他の単語のことは一旦忘れ、自分自身が持つ情報をより深く、洗練された表現へと昇華させていくのです。これは、詩人が推敲を重ね、一語の純度を高める作業に似ています。
5. 情報の抽出と生成:エンコーダー(Encoder)とデコーダー(Decoder)の役割
これらの計算は、大きく分けて2つの「塔」の中で行われます。
- エンコーダー(Encoder):本質の抽出
- 「春はあけぼの」という入力を受け取り、その文脈、文法、情景を一撃で抜き出します。
- ここで重要なのが「残差接続」です。元の「春」という言葉の響きを忘れないよう、計算結果に元の入力を足し合わせることで、情報の命脈を保ち続けます。
- デコーダー(Decoder):言葉の紡ぎ出し
- エンコーダーが抽出した特徴を受け取り、1トークンずつ「Spring... is...」と言葉を紡ぎ出します。
- マスク付き自己注意: 生成中、デコーダーは未来の言葉をカンニングしてはいけません。まだ見ぬ未来の言葉にモザイク(マスク)をかけ、これまでに語った自分の言葉だけを振り返りながら、次の一歩を決めます。
6. ベクトルから再び言葉へ:逆埋め込み(Un-embedding)と予測
デコーダーの最上階に到達したとき、そこには文脈がパンパンに詰まった�「最強のベクトル」が生まれています。しかし、これはまだAIの内部言語です。これを再び人間の言葉へと戻すのが、逆埋め込みという美しい対称性のプロセスです。
- 原点への回帰(逆埋め込み): 最後に得られたベクトルと、最初に使った「埋め込み行列 E」を再び照らし合わせます。入り口で使った地図を、出口でも使うという美しい対称性がここにあります。
- 確率の雨(ソフトマックス): 地図の中で最も似ている単語(例えば "Spring")がどこかを計算し、各単語が選ばれる確率分布を算出します。
- 言葉の誕生: 最も確率が高い、あるいは最も文脈に相応しい単語を太字で決定し、出力します。
- 終わりのサイン: これを繰り返し、「End of Sentence(EOS)」という終わりの合図が出るまで、AIは言葉を紡ぎ続けます。
こうして、「春はあけぼの」は時空を超え、新しい言語の調べとなって私たちの元へ届くのです。
7. まとめ:Transformerがつなぐ知能の未来
いかがでしたか?Transformerの全体像を振り返ると、そこには驚くほどエレガントな秩序があります。
- 言葉を「数値の地図」上の座標(ベクトル)として捉えること。
- 自己注意(Attention)が、離れた言葉同士を対話させ、文脈という命を吹き込むこと。
- エンコーダーとデコーダーが協力し、一撃で本質を掴み、��一歩ずつ未来を紡ぐこと。
自己注意(Attention)こそが、単なる数値の列を「生きた文脈」へと変える魔法の心臓部です。 この仕組みを理解したあなたは、AIがただ計算をしているのではなく、言葉の海の中で意味を編み上げているその崇高なプロセスを覗き見る鍵を手に入れたのです。
言葉がつながり、意味が生まれる。その喜びを、AIもまた複雑な行列計算の果てに感じているのかもしれません。この知能の未来を、共に歩んでいきましょう。
Transformer移行と次世代AI基盤構築のための戦略的選定ガイド
1. イントロダクション:現代AIアーキテクチャのパラダイムシフト
AI技術の進展は、特定タスク向けの個別最適化モデルから、汎用的な基礎モデル(Foundation Models)の活用へと劇的な変化を遂げました。このパラダイムシフトの中心に位置するのが「Transformer」です。現在、Transformerは自然言語処理(NLP)のみならず、画像認識(ViT)、画像生成、さらにはマルチモーダル基盤として、AI競争力を左右する「共通言語」となりました。
ビジネスリーダーにとって、アーキテクチャの選択は単なる技術的決定ではなく、計算資源の投資効率とスケーラビリティを決定づける戦略的判断です。本ガイドでは、なぜTransformerが「生成時代の新しい教科書」となり得たのか、そのメカニズムと戦略的意義をプロフェッショナルの視点から詳述します。
2. 技術的負債の検証:RNNおよびCNNの構造的限界
Transformer以前の主流であったRNN(再帰型ニューラルネットワーク)やCNN(畳み込みニューラルネットワーク)は、大規模化(スケーリング)において深刻な技術的制約を抱えていました。
- RNNの逐次処理による「ハードウェア活用率の天井」
RNNは情報を時系列に沿って一つずつ処理する構造であり、前のタイムステップの計算が完了するまで次の計算に移ることができません。この逐次的な性質は、現代のGPUが得意とする高度な並列演算能力を著しく阻害します。大規模モデルの構築において、ハードウェア活用率の低さは開発コストの増大と訓練時間の非現実的な長期化を招き、経済的に持続不可能な「ハードの天井」となっていました。
- CNNの局所性と大域的文脈のジレンマ
画像処理で強みを発揮したCNNは、データの局所的特徴を捉えるには優れています。しかし、長距離の要素間の関係性を把握するためには、層を深く積み重ねる必要があり、これが勾配消失リスクやアーキテクチャの複雑化を招いていました。大域的な文脈理解を単一層で実現できない非効率性が、モデルのスケーリングを妨げる要因となっていたのです。
これらの構造的限界は、単なる処理速度の問題ではなく、モデルが巨大なデータから複雑な概念を抽出する際の「成長限界」を意味していました。
3. Transformerの本質的優位性:並列計算と長距離依存性の解決
2017年の『Attention is All You Need』によるパラダイムシフトは、RNNやCNNを一切排除し、「自己注意機構(Self-Attention)」のみで構築するという革新的な提案から始まりました。
自己注意機構(Self-Attention)による並列性の確保
Transformerは、入力された全トークンを同時に処理できる「全域参照型」の構造を持ちます。各トークンの計算が互いに依存しないため、GPUの計算リソースを極限まで引き出すことが可能です。これにより、数兆トークン規模のデータセットを用いた学習が現実的な時間枠で可能となりました。
長距離依存�性の克服
文脈理解において、Transformerは距離の制約を完全に無効化します。「本の虫」というメタファーを例に取れば、どれほど物理的に離れた位置に「本」という言葉があっても、モデルは直接的な注意(Attention)を向けて関係性を数値化できます。
比較項目 RNN(従来型) Transformer(次世代型) 計算構造 逐次処理型: 並列化が困難 全域参照型: GPUに最適化 ハードウェア効率 低い(ハードウェアの天井) 極めて高い(スケールに適正) 文脈参照 距離が離れると忘却しやすい 距離に関わらず直接参照が可能 スケーラビリティ パラメータ増大に伴い学習が困難 大規模モデル構築に極めて適正 4. 構造的解剖:エンコーダー・デコーダーと注意機構のメカニズム
Transformerの優位性を支えるのは、高度に洗練された数学的構造です。
Q(Query)、K(Key)、V(Value)の論理的役割
Attentionプロセスは、入力ベクトル Z に対し、学習可能な重み行列 W_Q, W_K, W_V を乗じることで以下の役割を生成します。
- Query (Q) / Key (K): 内積計算(類似度)により、「どこ��に注目すべきか」というアテンションマップを構築。
- Value (V): 算出された重みに基づき、「何を抽出するか」という具体的な情報を伝搬。
マルチヘッド・アテンションの戦略的意義
複数の注意機構を並列に走らせることで、文法的特徴、常識的文脈、専門的知識など、多角的な特徴抽出を同時に行います。各ヘッドが異なる次元から情報を捉えることで、モデルの表現力は飛躍的に向上しました。
埋め込み(Embedding)と生成メカニズム
- Positional Encoding: 並列処理で失われる順序情報を P_i というベクトルとして付与します。ただし、近年の研究ではこの必要性について議論(Skepticism)があり、RoPE(回転位置行列)などの進化した手法への移行が進んでいます。
- 生成の制御(BOS/EOS): デコーダーは「BOS(文章開始)」トークンから生成を開始し、「EOS(文章終了)」トークンを予測した時点で生成を停止します。出力の質を高めるため、各ステップで複数の候補を保持する「ビームサーチ(Beam Search)」が広く採用されています。
隠れた強み:D_{model} の一貫性と「ロジットレンズ」
Transformerの特筆すべき設計は、各層を通るベクトルの次元数(D_{model})が一定に保たれている点です。この一貫性は、中間層の出力をデコーダーの最終出力層に直接投入し、モデルが「今何を考えているか」を可視化する「ロジットレンズ(Logit Lens)」という手法を可能にしました。これにより、ブラックボックス化しがちな深層学習モデルに「透明性」という戦略的価値をもたらしています。
5. 進化系統と現在の技術トレンド:BERTからGPT、そしてViT/MoEへ
Transformerという基盤は、その用途に応じて高度に分化し、進化を続けています。
アーキテクチャ進化系統と戦略的価値
系統 代表モデル 主要な強み・用途 戦略的価値 Encoder系 BERT, ViT 文脈抽出、意味理解、画像認識 高精度な分類・検索性能 Decoder系 GPT-4, Llama 自己回帰的な文章生成、対話 高度な推論・コンテンツ生成 最適化/MoE Mixtral (MoE) 専門家ネットワークの動的選択 推論コスト vs 能力の最適化 最新の最適化:行列の再利用とMoE
- 埋め込み行列(E)と逆埋め込み(E^T)の再利用: 効率的なアーキテクチャでは、入力時に使用した単語辞書行列 E を、最終出力時にトークンを予測するための行列 E^T として再利用し、パラメータ数の削減と効率化を図っています。
- Mixture of Experts (MoE): 巨大な知識ベースを持ちながら、推論時には必要な専門家(Expert)のみを稼働させることで、「スケーリング(知識量)」と「スピード(推論効率)」のトレードオフを解消しています。GPT-4oなどの最新モデルの背景にあるのは、この「実用的な最適化」の追求です。
6. 総括:技術意思決定者のためのアーキテクチャ選定指針
Transformerは、現代の計算資源の特質(並列性)とデータの性質(長距離依存性)を極限まで活用するために設計された、極めて合理的なアーキテクチャです。
本ドキュメントで解説した D_{model} の一貫性やロジットレンズの概念が示す通り、Transformerはもはや不可解なブラックボックスではありません。構造的な透明性を持ち、内部の「思考過程」を予測・最適化可能な「ホワイトボックス」へと近づきつつあります。
技術意思決定者への提言: 今後のAI活用において重要なのは、単に「どのモデルを採用するか」という表面的な選択ではありません。アーキテクチャの内部メカニズムを理解し、それがハードウェア効率や推論コストにどう直結するかを見極める「アーキテクチャ・リテラシー」です。Transformerという堅牢な基盤への理解を深めることは、モデルの振る舞いを予測し、自社の課題に対して真に最適なシステムを選定・構築するための、唯一の戦略的な道標となるでしょう。
以下、mind map から
全体像(Encoder-Decoder)
提供されたソースによると、「Transformerの徹底解読」という文脈において、Transformerの全体像(Encoder-Decoder構造)は、ある系列(例えば日本語の文)を別の系列(例えば英語の文)に変換する「Sequence-to-Sequence(Seq2Seq)」のタスクを解くためのモデルとして説明されています。
全体像は大きく「エンコーダー(Encoder)」と「デコーダー(Decoder)」の2つの役割に分かれており、それぞれの機能と特徴は以下の通りです。
1. エンコーダー(Encoder)の役割
エンコーダーは、入力されたテキスト(トークン列)から意味的・文法的な特徴量を抽出する役割を担います。
- 入力の処理: テキストは計算可能なベクトルに変換され(埋め込み)、並び順を認識させるための情報(位置符号)が付与されます。
- 文脈の理解(自己注意機構): 各トークンを個別に処理するのではなく、「自己注意機構(Self-Attention)」を用いて系列全体を参照します。これにより、例えば「本の虫」という言葉が単なる昆虫ではなく比喩表現であるといった、文脈を考慮した特徴抽出が可能になります。
- 構造: 「マルチヘッド自己注意機構」と「フィードフォワードネットワーク」からなるブロックを��、N回(例えば6回や12回など)積み重ねた構造になっています。
2. デコーダー(Decoder)の役割
デコーダーは、エンコーダーが抽出した特徴と、デコーダー自身が過去に生成したテキストを入力として受け取り、次に続くべきトークンを予測・生成するネットワークです。
- トークンの生成ループ: 1回の予測で1つのトークンを出力し、それを次のステップの自身の入力に追加してループを回していく「自己回帰的」な構造を持っています。
- デコーダー特有の構造: エンコーダーと同様にブロックをN回繰り返しますが、内部には以下の特有の仕組みがあります。
- マスク付き自己注意機構: 学習時に未来の正解トークン(まだ予測していないはずのトークン)をカンニングできないようにマスクをかけ、推論時と同じ条件に揃えます。
- 交差注意機構(Cross-Attention): デコーダーがこれまでに出力した情報と、エンコーダーが抽出した入力側の特徴量を混ぜ合わせます。これにより「今何を出力していて、何を翻訳すべきか」をすり合わせます。
アーキテクチャ全体の強み
このEncoder-Decoder構造全体を通じた最大の強みは、RNN(再帰型ニューラルネットワーク)やCNN(畳み込みニューラルネットワーク)を使わず、「注意機構(Attention)」のみで構築されている点です。 これにより、従来のモデルでは両立が難しかった「文中の離れた単語同士の依存関係(長距離依存)の理解」と「効率的な並列計算」を見事に両立させていると解説されています。
主要コンポーネント
提供されたソースにおける「Transformerの徹底解読」という文脈では、前回の「Encoder-Decoder」という全体像の中身を構成する、具体的な「主要コンポーネント(部品)」の役割と仕組みについて詳細に解説されています。
ソースは、これらのコンポーネントがどのように連携してテキストの処理を行っているかについて、大きく以下の4つのステップに分けて説明しています。
1. 入力データの準備(ベクトル化と語順の認識)
Transformerはテキストをそのまま計算できないため、処理の前準備として2つのコンポーネントが働きます。
- 埋め込み(Embedding): 入力されたテキストの断片(トークン)を、モデルが計算可能な固定次元(Dモデル次元)の「ベクトル」に変換します。
- 位置符号化(Positional Encoding / 1符号): その後の注意機構には「トークンが並んでいる順番」を認識する能力がないため、埋め込みベクトルに対して「文中の何番目にあるか」という位置情報を足し合わせます。
2. コアとなる文脈理解(注意機構 / Attention)
Transformerの心臓部であり、文中の単語同士の繋がりを理解するためのコンポーネントです。
- 自己注意機構(Self-Attention): 各トークンからクエリ(Query: 検索の起点)、キー(Key: 検索先)、バリュー(Value: 実際の情報)という3つのベクトルを作り出します。クエリとキーの内積を計算して「どのトークンにどれくらい注意を向けるべきか(注意重み)」を算出し、その割合に応じてバリューを混ぜ合わせることで、文脈を反映した新しいベクトルを作ります。
- マルチヘッド自己注意機構(Multi-Head Self-Attention): 1つの大きな自己注意機構を回すのではなく、ベクトルを小さく分割して「複数の自己注意機構(ヘッド)」を並列で実行します。これにより、文法的な繋がりや意味的な繋がりなど、複数の異なる観点から同時に特徴を抽出できます。
- マスク付き自己注意機構(Masked Self-Attention): デコーダー特有のコンポーネントです。学習時に「未来の正解トークン」をカンニングしてしまうのを防ぐため、未来のトークンへの注意重みを強制的にゼロ(マスク)にします。
- 交差注意機構(Cross-Attention): こちらもデコーダー特有です。デコーダー自身が生成したクエリと、エンコーダーが抽出したキー・バリューを掛け合わせます。これにより「自分がこれまで何を出力したか」と「入力文の何を変換すべきか」をすり合わせます。
3. 情報の変換と学習の安定化
注意機構で抽出された特徴をさらに処理し、深いネットワークでも学習がうまく進むようにするコンポーネントです。
- フィードフォワードネットワーク(Feed-Forward Network): 注意機構で混ざり合ったベクトルに対し、トークンごとに独立して線形変換と活性化関数(ReLU)を適用し、情報を変換します。
- 残差接続(Residual Connection)と層正規化(Layer Normalization): 各層(注意機構やフィードフォワード層)の処理結果に、処理する前の元の入力ベクトルを足し合わせます(残差接続)。これにより、情報が�失われるのを防ぎ、計算の流れを追いやすくすることでモデルの学習を安定させます。
4. 最終出力の生成
- 逆埋め込み(Un-embedding)とソフトマックス(Softmax): デコーダーの最終段階で、ここまで処理されてきたベクトルを、辞書に登録されている全トークンの「確率分布」に変換します。この確率分布に基づき、次に続く可能性が最も高いトークンが選ばれます(ビームサーチなどの探索手法も用いられます)。
ソースは、これら一つ一つのコンポーネント(特にQuery/Key/Valueを用いた自己注意機構)が精巧に組み合わさることで、これまでのモデルでは難しかった「文脈の正確な理解(長距離依存)」と「効率的な並列計算」の両立が実現されていると説明しています。
前処理・後処理
これまでの解説(Encoder-Decoderの全体像や、注意機構などの主要コンポーネント)を踏まえ、ソースが語るTransformerの「前処理」と「後処理」について説明します。
Transformerはテキストをそのまま計算することができないため、入り口(前処理)でテキストをモデルが理解できる「数値の列」に変換し、出口(後処理)で計算結果を再び人間が理解できる「テキスト」に戻す作業が必要不可欠です。
ソースでは、これらの処理が以下のように解説されています。
1. 前処理:テキストを計算可能なベクトルにする
入力されたテキスト(トークン列)をTransformerに投入する前段として、以下の2つのステップが行われます。
- 埋め込み(Embedding) テキストを直接処理できないため、辞書(例えば3万種類のトークンリスト)の情報を使い、各トークンを固定次元(Dモデル次元)の「ベクトル」に変換します。具体的には、巨大な埋め込み行列の中から、該当するトークンの意味的・文法的な特徴を表すベクトルを抽出する作業です。
- 位置符号化(Positional Encoding / 位置情報の付与) Transformerの心臓部である「自己注意機構(Self-Attention)」は文脈を広く理解できる反面、「トークンがどういう順番で並んでいるか」を認識する能力が全くありません。そこで、埋め込みで得られたベクトルに対して、「このトークンは文中の何番目にあるか」を示す固有の位置ベクトルを足し算します。これにより、初めてモデルが「語順」を認識できるようになります。
2. 後処理:計算結果をテキスト(�確率)に戻す
デコーダー側で「次に続くべきトークンの予測」に向けた複雑な計算が終わると、最後に以下のような後処理が行われます。
- 逆埋め込み(Un-embedding)
デコーダーの最後のステップから出力されたベクトル(Dモデル次元)を、再び辞書の全トークン数(V次元)へと変換し直します。具体的には、デコーダーの最終出力ベクトルと、辞書内にある全トークンの埋め込みベクトルとの間で「内積(類似度)」を計算します。これにより、出力ベクトルと最も似ている(=次に来る可能性が高い)トークンが炙り出されます。
- ソフトマックス(Softmax)による確率分布化
逆埋め込みで得られた全トークンに対する類似度スコアを、ソフトマックス関数に適用します。これにより、スコアが「次にどのトークンが来るか」の確率分布(合計すると1になる割合)に変換されます。
- 予測の決定とビームサーチ(Beam Search)
単純に「その場で一番確率の高いトークン」を選ぶこともできますが、より自然な文章を生成するために「ビームサーチ」と呼ばれる探索手法がよく使われます。これは、各ステップで確率上位の候補を複数保持しておき、最終的に「系列全体として最も確率が高く、自然な並び」になるものを選択する手法です。
- 終了判定 この予測ループを繰り返し、「生成終了(End of Sentence)」を意味する特殊なトークンが予測された時点で、テキストの生成が完了となります。
このように、高度なAttentionの計算を成立させるためには、入り口での「埋め込み・位置情報の付与」と、出口での「逆埋め込み・確率化」という前処理・後処理が非常に重要な役割を担っていると説明されています。
情報源
動画(1:48:51)
圧倒的図解で学ぶ「Transformer」徹底解読【Attention is All You Need】
https://www.youtube.com/watch?v=9Tu8H7wPVWo
20,000 views 2025/09/07
Attention is All You Need(Vaswani+ 2017)で提案された最重要モデル「Transformer」を徹底解説します。
📝 論文:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
(2026-03-15)