Philip Corso の息子の証言
· 67 min read
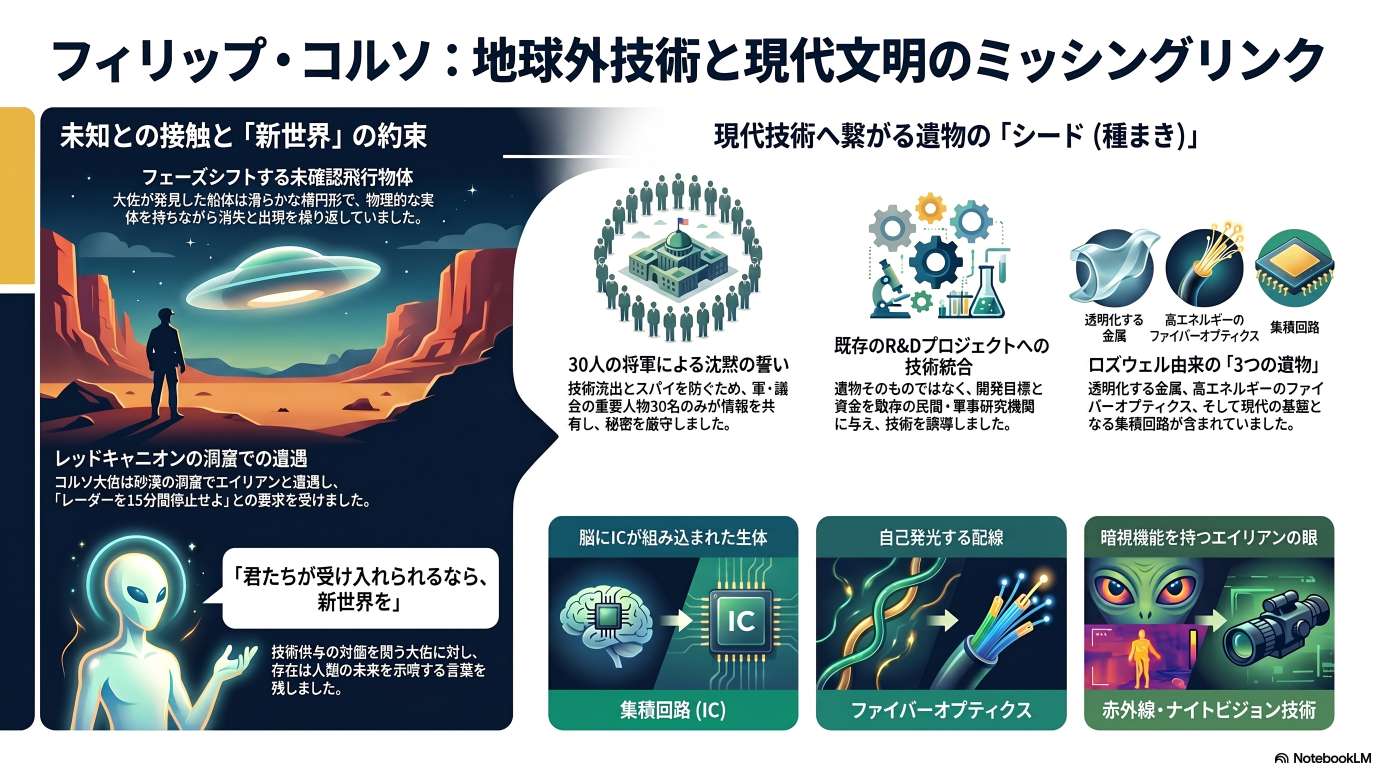
(全体俯瞰 : AI 生成) click で拡大
 (情報源)
(情報源)
前置き+コメント
過去記事、
Philip Corso の息子の証言:文字起こし (2025-04-24)
の証言部分に絞って AI で整理した。
以下、情報源を NotebookLM で整理した内容。
要旨
このテキストは、 Philip Corso 大佐の息子が、ロズウェル事件とその後の機密技術の隠蔽に関する父親の衝撃的な証言を詳しく語ったものです。
大佐は軍の要職に就いていた際、異星人の遺物を民間企業へ提供し、レーザーや集積回路などの現代技術へと転換させる極秘任務を担っていました。証言によれば、これらは単なる技術開発ではなく、地球外生命体の脅威に備えた軍事的防衛策の一環として進めら��れたといいます。
また、冷戦の裏側で進んでいた惑星防衛システムの構築や、政府・宗教機関が共有していた宇宙の真実についても触れられています。この記録は、数十年にわたり沈黙を守り続けた軍人が、死の間際に家族や世界へ託した未知の歴史の断片を浮き彫りにしています。