Qwen 3.6-35B-A3B : API 課金破産を回避する local LLM の実現の可能性
(全体俯瞰 : AI 生成) click で拡大
 (情報源)
(情報源)
前置き+コメント
先月の過去記事で
Frieve(小林由幸) : Local AI の幻想を捨てろ! (2026-03-30)
という意見を取り上げたが、Local AI 否定派の常識は必ずしも成立しない。たとえば、
- 社外秘のデータを扱う用途
- 膨大なデータを一貫性を持たせてあらゆる方向から徹底的に長時間かけて分析させる用途
- AI 企業の設けた制限なしに AI を使う用途
などでは、急激に進化しつつある local AI でないと対応できない。
こういった事例、とくに 2. では処理すべきデータ量、処理時間、コンテキスト長が膨れ上がるが、それをクラウド AI のAPI 課金で処理すると破産しかねない。
最近公開された Qwen 3.6 などはその叩き台として使えそうな気がする。ただし、一般的な普及価格帯の GPU ならば RAM 128GB 以上が前提だとあるので、この際、Windows ベースではなく、Mac Studio Ultra あたりを導入した方が良いかも。
【重要】システムRAMへのオフロードに関する�警告: RTX 4070(12GB VRAM)等のミドルレンジ環境での動作事例(7.19 sec/token)がありますが、これは不足分をシステムメモリ(RAM)で補った場合の数値です。この運用には128GB以上の大容量システムRAMが前提となります。RAM容量が不足(16GB〜32GB等)している場合、オフロード機能は動作せず、システムクラッシュを招くリスクが極めて高くなります。
以下、情報源を NotebookLM で整理した内容。
要旨
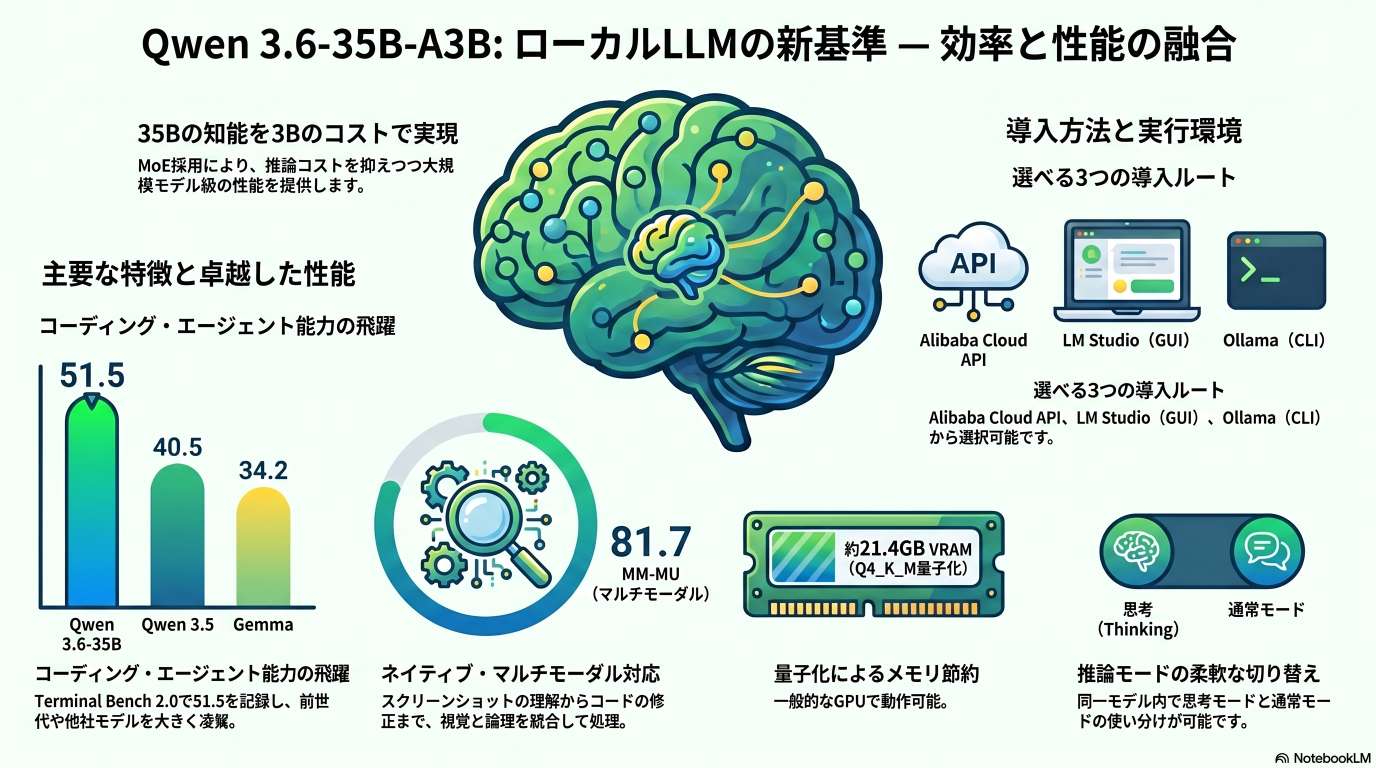
このテキストは、Alibaba Cloudが公開した最新のマルチモーダルAIモデル「Qwen 3.6-35B-A3B」の性能と導入方法を詳しく解説しています。
このモデルは、350億パラメータという規模を持ちながら、推論時には30億パラメータのみを活性化させる効率的なアーキテクチャを採用しているのが特徴です。特にコーディング能力やエージェント機能において優れたスコアを記録しており、画像認識を含むマルチモーダルなタスクにも標準で対応しています。
利用者は、AlibabaのAPI経由だけでなく、LM StudioやOllamaを通じて個人のMacBookやRTX 4070搭載PCでローカル実行することが可能です。高いコストパフォーマンスとApache 2.0ライセンスによる柔軟性を備えていますが、実務での導入には推論の冗長性や特定条件下での速度低下といった課題も考慮する必要があります。
総じて、エンジニアリングや視覚的推��論を効率化したいユーザーにとって、強力な選択肢となるモデルであると結論付けています。
@@ no search index start
目次
- 前置き+コメント
- 要旨
- Qwen 3.6-35B-A3B 技術ブリーフィング:次世代MoEモデルによるソフトウェア工学とマルチモーダル機能の革新
- Qwen 3.6-35B-A3B モデル仕様とベンチマーク比較
- Qwen 3.6-35B-A3B 導入運用ガイド:効率的なデプロイと実運用への指針
- 情報源
@@ no search index stop
Qwen 3.6-35B-A3B 技術ブリーフィング:次世代MoEモデルによるソフトウェア工学とマルチモーダル機能の革新
エグゼクティブ・サマリー
Qwen 3.6-35B-A3Bは、Alibaba Cloudによって2026年4月16日に公開された、Apache 2.0ライセンスに基づくオープンな因果関係マルチモーダルAIモデルです。本モデルの最大の特徴は、「大規模モデルの性能を小規模モデルの運用コストで実現する」点にあります。
混合エキスパート(MoE)アーキテクチャを採用し、総パラメータ数350億のうち、トークンごとにアクティブになるのはわずか30億パラメータに抑えられています。これにより、ローカルのMacBookや消費者向けGPU(RTX 4070等)でも動作可能なサイズでありながら、フルリポジトリを扱うソフトウェアエンジニアリングタスクにおいて、従来の重量級モデルに匹敵、あるいは凌駕する性能を発揮します。コード生成、エージェント機能、視覚理解を統合した本モデルは、特に開発ワークフローの自動化において強力な選択肢となります。
1. モデルの基本仕様とアーキテクチャ
Qwen 3.6-35B-A3Bは、効率性と多機能性を両立させるために設計された3つの主要な柱に基づいています。
- スパースMoE(Mixture of Experts):
- 総パラメータ数:350億(35B)
- アクティブパラメータ数:トークンあたり30億(3B)
- この設計により、推論効率が大幅に向上しており、運用フットプリントを最小限に抑えています。
- 統合されたマルチモーダル機能: ビジョン�エンコーダーをベースのチェックポイントから統合。後付けのパッチではなく、設計段階から視覚情報(スクリーンショット、図解など)を理解し、それに基づいたコード修正やバグ修正を行う能力を備えています。
- 広範なコンテキストと多言語対応:
- ネイティブコンテキスト:262,144トークン
- 対応言語:200以上の言語と方言をカバー(Qwen 3.5の機能を継承・拡張)
- 柔軟な推論モード: 同一のチェックポイント内で、推論(Thinking)モードと非推論(Non-thinking)モードの両方をサポートしています。
2. ベンチマーク・パフォーマンス分析
本モデルは、特にコーディングおよびエージェント関連のタスクで顕著なスコアを記録しています。
2.1 コーディングおよびエージェント機能
ベンチマーク スコア 比較対象・備考 Sench verified 73.4 ソフトウェア工学タスクの高度な解決能力 Terminal Bench 2.0 51.5 前モデルQwen 3.5(40.5)、Gemma(34.2)を大きく上回る SWE Bench Pro 49.5 実世界のソフトウェアエージェント性能 SWE Bench Multilingual 67.2 多言語環境下でのコーディング能力 NL2Repo (Long Horizon) 29.4 大規模リポジトリの理解と操作 MCP Mark 37.0 エージェント機能の統合指標 2.2 推論およびマルチモーダル性能
- 数学・論理: GPQA Diamond (86.0)、Harvard MIT Mathematics Tournament (83.6)
- マルチモーダル理解: mmMU (81.7)、Real World QA (85.3) これらの数値は、推論コストが大幅に低いモデルであることを考慮すると、極めて高い投資対効果を示しています。
3. 実装とデプロイメント・オプション
Qwen 3.6-35B-A3Bは、クラウドからローカル環境まで柔軟なデプロイが可能です。
3.1 管理型API(Alibaba Cloud Model Studio)
- OpenAI SDK互換のエンドポイントを提供。
- 注意点として、APIキーとエンドポイントはリージョン(中国本土と国際)ごとに分かれており、レート制限(429エラー時は約1分で回復)に注意が必要です。
3.2 ローカル実行
環境に応じた複数のツールが利用可能です。
- LM Studio: 視覚的インターフェースを好むユーザー向け。Apple Silicon用のMLX形式やNVIDIA GPU用のGGUF形式を自動検出し、ノーコードでOpenAI互換サーバーを構築可能。
- Ollama: コマンドライン(ollama run qwen3.6-35BA3B)で即座に実行可能。
- 開発者向けライブラリ: Hugging Face Transformers、vLLM、SGLang、MLX、K-Transformersなどの主要フレームワークをフルサポート。
3.3 量子化とハードウェア要求
形式 推定VRAM容量 推奨環境 BF16 (未量子化) 約69.38 GB ハイエンドデータセンター用GPU Q4_K_M (4ビット量子化) 約21.39 GB 消費者向けハイエンドGPU (RTX 3090/4090等) 実機テスト事例: RTX 4070 (12GB VRAM) + 128GB RAMの構成では、4ビット量子化モデルが7.19秒/トークンで動作。
4. 課題と検討事項
導入にあたっては、以下の制限事項を考慮する必要があります。
- 冗長性(Verbosity): 推論(Thinking)モードがデフォルトで有効なため、回答が長くなる傾向があり、出力トークンコストが増大する可能性があります。
- 知識の一般性: 一般知識や特定の抽象的推論ベンチマーク(Arena Hard BV2、HLEなど)では、必ずしも同クラスの他モデルに対して圧倒的な優位性を持っているわけではありません。
- 量子化の最適化: GGUF形式の量子化において、Qwen 3.5よりも推論速度が低下するケースや、ツール呼び出し(Tool Calling)がBF16環境でも失敗する場合があるとの報告があります。
- ベンチマークへの適合懸念: 一部の技術コミュニティからは、公開されているコーディングベンチマークに対する過学習(汚染)の可能性も指摘されています。
5. 結論と推奨事項
Qwen 3.6-35B-A3Bは、「コード作成、ターミナルエージェント、大規模リポジトリ操作、複雑なドキュメントのOCR、視覚的推論」を、自社管理下(ローカル)で実行したい組織にとって、現在最も有力な選択肢の一つです。
純粋な百科事典的知識や抽象的な思考力を最優先とする場合は他モデルとの比較検討が必要ですが、実務的なエンジニアリングタスクにおいては、比類のない性能対コスト比を提供します。まずは実際の業務データを用いて、ローカル環境でラテンシーと品質を測定し、エージェントワークフローへの適合性を評価することを推奨します。
Qwen 3.6-35B-A3B モデル仕様とベンチマーク比較
デル名 パラメータ数 (総計/アクティブ) ベンチマーク指標 スコア/パフォーマンス 主な機能・特徴 推論環境・ツール VRAM要件 (推定) Qwen 3.6-35B-A3B 350億 (総計) / 30億 (アクティブ) SWE-bench Verified, Terminal Bench 2.0, SWE-bench Pro, SWE-bench Multilingual, Qwen Cloud Bench, Qwen Webch (Web artifacts), NL2Repo, MCP Mark, GPQA Diamond, HMMT (Harvard MIT Mathematics Tournament), MMLU, Real World QA SWE-bench Verified: 73.4, Terminal Bench 2.0: 51.5, SWE-bench Pro: 49.5, SWE-bench Multilingual: 67.2, Qwen Cloud Bench: 52.6, Qwen Webch: 1397 (ELO), NL2Repo: 29.4, MCP Mark: 37.0, GPQA Diamond: 86.0, HMMT: 83.6, MMLU: 81.7, Real World QA: 85.3 因果推論マルチモデル、統合されたビジョンエンコーダ、256Kトークンのネイティブコンテキスト、思考(Thinking)・非思考モードの統合、200以上の言語・方言への対応、エージェント機能(ツール使用、ターミナル操作、大規模リポジトリ作業)に特化 Alibaba Cloud Model Studio (API), LM Studio, Ollama, Hugging Face Transformers, vLLM, SGLang, MLX (Apple Silicon), KTransformers, llama.cpp BF16(未量子化): 約69.38 GB, Q4_K_M(4ビット量子化): 約21.39 GB [1] Probando Qwen3.6-35B Localmente (RTX 4070): ¿El Nuevo Rey del Código?
Qwen 3.6-35B-A3B 導入運用ガイド:効率的なデプロイと実運用への指針
1. エグゼクティブ・サマリー:Qwen 3.6の戦略的価値
現代のエンタープライズAIインフラ戦略において、計算リソースの最適化と推論精度の高度な両立は、TCO(総所有コスト)削減に直結する最重要課題です。2026年4��月16日にAlibaba CloudからリリースされたQwen 3.6-35B-A3Bは、この課題に対する決定的なソリューションを提示しています。
本モデルの最大の技術的特異点は、350億(35B)の総パラメータを保持しながら、推論時にはわずか30億(3B)のアクティブパラメータのみを駆動させるMoE(Mixture of Experts)アーキテクチャにあります。これにより、大規模モデル級の高度な推論品質を維持しつつ、アクティブな計算コストを従来の1/10近くまで圧縮。さらに、Qwen 3.6では「Thinking(思考)/ Non-thinking」モードの融合が実現されており、タスクの複雑性に応じて推論プロセスの冗長性を制御できる柔軟性を備えています。
Qwen 3.6-35B-A3Bの主要な戦略的スペック:
- アーキテクチャ: 総パラメータ35B、アクティブパラメータ3Bの疎なMoE構造。
- 推論効率: 小規模モデル並みの運用コストで、大規模モデルに匹敵する「エージェント機能」を提供。
- コンテキスト長: 最大260,144トークンのネイティブ長文対応。
- マルチモーダル統合: ビジョンエンコーダーをベースモデルに初期段階から統合。
- ライセンス: 商用利用に極めて柔軟なApache 2.0を採用。
- リリース日: 2026年4月16日(Hugging Face / Model Scopeにて公開)。
次章では、この革新的なアーキテクチャが具体的にどのようなパフォーマンス向上をもたらしているか、定量的なデータを基に分析します。
2. 技術的特性とパフォーマンス分析
Qwen 3.6-35B-A3Bは、単なる言語生成モデルを超え、ターミナル操作、リポジトリ理解、ツール利用といった「エージェント・ワークフロー」の実行エンジンとして最適化されています。前世代(3.5)や競合するGemmaシリーズと比較して、特にエンジニアリングの実務領域で顕著な優位性を示しています。
一方で、ソリューションアーキテクトとしては、本モデルが「全能」ではない点に注意が必要です。ベンチマークデータによれば、コード生成やエージェント機能では圧倒的ですが、Arena HardやHLEといった「一般知識」や「抽象的推論」の領域では、前世代から横ばい、あるいは競合に対して決定的な差をつけていないケースも見受けられます。
主要ベンチマーク比較表:
Benchmark Qwen 3.6-35B-A3B Qwen 3.5 Gemma / Others Terminal Bench 2.0 51.5 40.5 34.2 SWE Bench Pro 49.5 - - Quen Webch (Web Artifacts) 1397 (ELO) - - NL2Repo (Long Horizon) 29.4 - - MCP Mark (Tool Use) 37.0 - - MMMU (Visual Reasoning) 81.7 - - GPQA Diamond (Reasoning) 86.0 - - このデータから、Qwen 3.6が「実務遂行型AI」として設計されていることが分かります。しかし、これら高いポテンシャルを安定して引き出すためには、ハードウェア側の物理的な制約を正確に把握しなければなりません。
3. ローカル環境におけるハードウェア要件とリソース最適化
インフラ設計において、VRAM(GPUメモリ)管理はモデルのレスポンス性能を左右する最大のボトルネックです。Qwen 3.6-35B-A3Bをローカルで運用する場合、量子化技術の選定がインフラコストに決定的な影響を与えます。
量子化レベル別 VRAM要件と推奨インフラ:
量子化形式 VRAM消費量 推奨GPU / 推奨構成 BF16 (Original) 約 69.38 GB A100 (80GB) / H100 等のサーバーグレード Q4_K_M (4-bit) 約 21.39 GB RTX 4090, RTX 3090, MacBook (M2/M3 Max) GGUF (更なる量子化) 20GB 未満 RTX 4080 (16GB) ※精度のトレードオフあり 【重要】システムRAMへのオフロードに関する警告: RTX 4070(12GB VRAM)等のミドルレンジ環境での動作事例(7.19 sec/token)がありますが、これは不足分をシステムメモリ(RAM)で補った場合の数値です。この運用には128GB以上の大容量システムRAMが前提となります。RAM容量が不足(16GB〜32GB等)している場合、オフロード機能は動作せず、システムクラッシュを招くリスクが極めて高くなります。
また、デプロイ時にはOSに応じたバックエンド(Mac環境ならllama.cppのMetal、NVIDIA環境ならCUDA)を適切に選択することで、推論のア�クセラレーションを最大化する必要があります。
4. デプロイメント・パスの選択と実装
実運用におけるデプロイメントは、スループット要求とハードウェア資産に基づいて選択します。
導入ルート 主要な特性・ツール 最適なユースケース GUI (LM Studio) MLX (Apple) / GGUF (NVIDIA) 自動検出。UIベース。 非エンジニアの検証、迅速なプロトタイピング。 CLI (Ollama) ollama run qwen3.6-35ba3b。バックエンドにllama.cpp使用。 開発環境へのAPI統合、軽量なスクリプト連携。 Production (vLLM/SGLang) K-Transformers、MLX、高性能ランタイム対応。 商用サービス、高スループットなエンタープライズ用途。 特に高負荷なプロダクション環境では、K-TransformersやvLLMを活用することで、MoE特有の疎な計算を最適化し、同時リクエスト処理能力を高めることが推奨されます。
5. Alibaba Cloud Model StudioによるAPI運用と制限事項
オンプレミスリソースが��不足している、あるいは弾力的なスケーラビリティが必要な場合は、マネージドAPIの活用が戦略的選択となります。
API運用管理チェックリスト:
- リージョン別エンドポイントの確認: 中国本土と国際リージョンでURLが異なります。構成管理に注意してください。
- SDK互換性設定: OpenAI互換SDKを使用。base_url と api_key の差し替えのみで移行可能です。
- レートリミット(429エラー)対応: アカウント単位のクォータに依存します。エラー時は通常1分程度の待機とリトライ戦略が必要です。
- セキュリティ管理: APIキーはリージョンごとに独立した機密情報として扱い、環境変数等で秘匿してください。
6. 実運用における課題と最適化の指針
導入後に直面する技術的・経済的リスクを回避するため、以下のトラブルシューティング・マトリクスに基づいた運用設計を行ってください。
トラブルシューティング&最適化マトリクス:
課題 ビジネス・運用への影響 具体的な回避・緩和策 Reasoningモードの冗長性 デフォルトで「Thinking」が有効なため、出力トークンが増大。コスト増の主因となる。 システムプロンプトで「non-thinking」を指定、または簡潔な回答を強制する。 ベンチマーク汚染の疑い 公開指標ほどの性能が実務で発揮されない可能性(Hacker News等で指摘)。 プライベートデータを用いた独自のPoCを実施し、実効性能を検証する。 Tool Callingの失敗 外部連携時のスキーマ解釈エラー。エージェントの信頼性低下。 BF16形式の採用、または関数定義(Prompt Engineering)の厳格化。 量子化モデルの速度低下 GGUF版がQwen 3.5より低速化するケースが報告されている。 vLLM等の最適化された推論エンジンの使用、ハードウェア構成の再評価。 7. 結論:導入へのロードマップ
Qwen 3.6-35B-A3Bは、高スループットな推論バックボーンとして、エージェント型ワークフローの構築に極めて強力な価値を提供します。導入に向けて、以下のステップで着手することを推奨します。
- フェーズ1:検証・評価(1〜3日) LM StudioやOllamaを使用し、まずはローカル環境で「コード生成」「OCR」「長文理解」の特定タスクにおける実力をエビデンスベースで測定してください。
- フェーズ2:インフラ最適化(1週間〜) 必要な精度とコスト(VRAM/トークンコスト)のバランスから、量子化(Q4)か、高精度(BF16/API)かのパスを決定します。
- フェーズ3:本格運用とガバナンス Alibaba Cloud Model Studio、あるいはvLLMを用いた自社プロダクション環境を構築。トークン消費のモニタリングとリトライ戦略を実装し、安定運用を開始します。
Qwen 3.6は、AIを単なる「相談相手」から「業務の実行主体」へと変革させる可能性を秘めています。本ガイドが、貴社のAIトランスフォーメーションにおける堅牢な礎となることを確信しています。
情報源
動画(9:19)
Probando Qwen3.6-35B Localmente (RTX 4070): ¿El Nuevo Rey del Código?
https://www.youtube.com/watch?v=x9-zL737eks
2,200 views 2026/04/20
(2026-04-21)